At Alphyn.AI, our Spark engineers work on non-trivial distributed computing problems — some of which make their way into the Alphyn Lakehouse platform as production-grade improvements. This post covers one such problem: the challenges of implementing Upsert Streaming in Iceberg, what equality delete files are and why they create read-time overhead, and how we optimized Apache Spark to reduce memory consumption and speed up data reads.

Background
Streaming data architectures have grown rapidly in adoption, particularly where data freshness is critical. In our platform we went down this path: to minimize data delivery latency into storage, we implemented Flink Upsert Streaming on top of Apache Iceberg — the open table format that has emerged as the de facto winner of the open table format wars, with full transactional support and efficient handling of large data volumes.
One of Apache Iceberg's key strengths is support for UPDATE, DELETE, and MERGE operations without a full table rewrite, available in Merge-on-Read mode since version 2 of the format specification.
In the early stages everything looked promising: Flink streaming jobs wrote reliably into Iceberg tables, and our Spark-based maintenance processes — using Iceberg's built-in procedures — ran without issues. On test environments with synthetic load the system behaved predictably and held up well.
Production, however, told a different story. Not long after go-live we hit a critical problem: the tables became nearly unreadable. Spark maintenance processes started failing in bulk with OutOfMemory (OOM) errors, and attempts to provision "enough" resources experimentally proved futile — required memory and execution time grew in a nonlinear, unpredictable way. Worse, while maintenance was running the table state kept deteriorating: new Flink commits were piling up additional equality delete files, compounding fragmentation and further slowing reads.
This article explains the limitations we encountered in Iceberg's Equality Delete implementation, why timely table maintenance is critical, and how we solved the problem.
Why We Use Spark for Table Maintenance
We run Iceberg maintenance on Spark for three reasons:
The Iceberg-on-Spark integration ships a complete set of maintenance procedures and covers every task we need — unlike the other engines in our platform;
Only Spark provides fine-grained tuning of individual maintenance procedures;
Spark lets us enforce hard resource limits on maintenance jobs without affecting any other running workloads.
The data file maintenance process consists of three stages:
read;
apply deletes;
write.
The real problems — in Spark and in other engines alike — occur during the read and delete-application stages. The rest of this post focuses on those.
What Equality Delete Is and Why It Appears
Iceberg supports two row-level deletion strategies:
Positional delete — deletes a specific row by its physical position (file + row index within that file). Useful when the writer knows exactly where a row lives.
Equality delete — deletes rows by matching one or more column values (e.g.,
customer_id = 123). This is the natural choice for streaming writes: the writer doesn't know which data file contains the old version of a row, so it simply records which values should be excluded.
When reading the table, Spark must merge data files with delete files to reconstruct the current state. To do this, Iceberg reads the equality delete files, builds sets (filters) of deleted values, and applies them to the data files partition by partition.
Table Update Semantics: CoW vs MoR
Copy-on-Write (CoW): every modification produces a new data file containing all current rows — old files are retired.
Merge-on-Read (MoR): inserts produce a new data file; deletes and updates produce delete files (positional or equality). The current state is reconstructed at read time by merging data files with delete files.
It is in MoR mode that delete files accumulate — in both count and size — placing increasing pressure on the mechanisms that process them.
How Equality Delete Caching Works in Iceberg on Spark
Delete application in Iceberg on Spark happens at the point of reading each data file. To optimize MoR table reads, Iceberg implements a delete-file cache that reduces S3 I/O by avoiding re-fetching the same files.
How the read filter is constructed
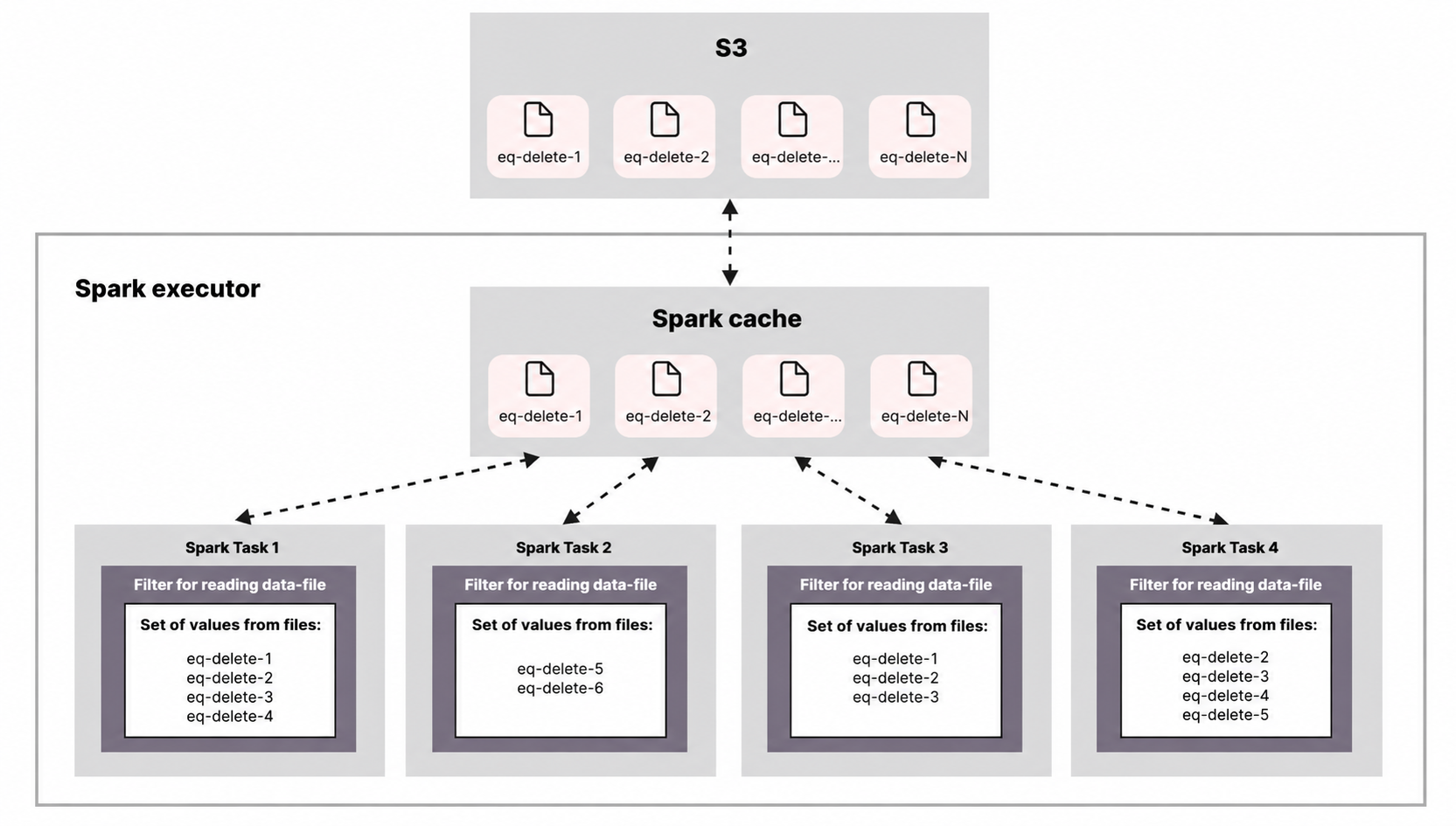
Applying equality delete files involves four layers of abstraction:
Compressed equality delete files on S3;
Compressed equality delete files in the in-memory cache;
A set of unique values derived from the relevant equality delete files, scoped to a specific data file being read;
Bloom filters built from those unique value sets, used during data file reads.
This architecture requires keeping both raw file data and its filter representation in memory simultaneously. The consequence: the more CPU cores and Spark tasks you have, the more memory you need — because each thread builds its own independent value set and filter.
For example, when reading a large data-file.parquet that contains multiple row groups, Spark can read each row group in a separate parallel task. All those tasks will load the same equality delete files and build nearly identical value sets and filters — effectively duplicating the data in memory.
How equality delete files are created and applied
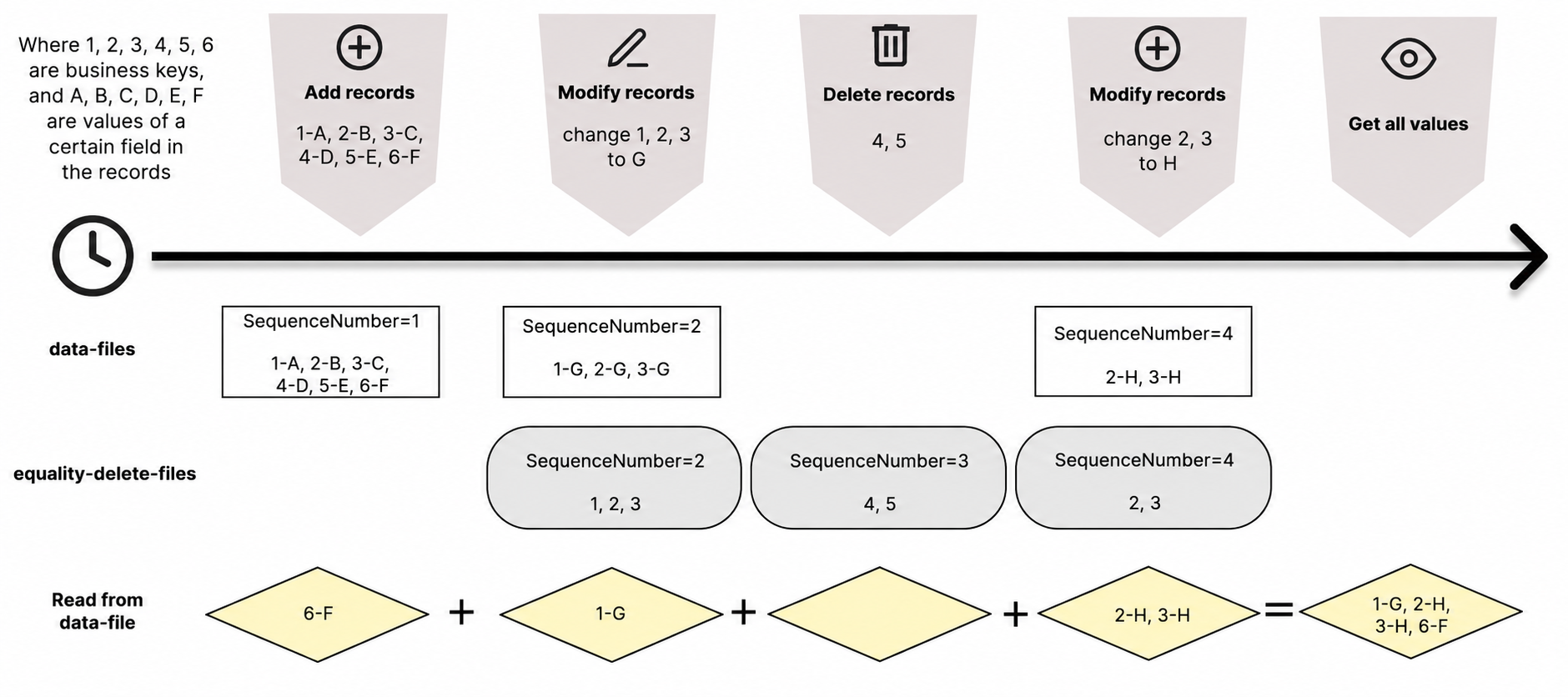
Every write operation on a Merge-on-Read table produces its own data file and equality delete file, each assigned the next SequenceNumber. To reconstruct the final state, all files are merged according to a defined set of rules.
To get the current value of a row, each data file must be read and all equality delete files with a higher SequenceNumber must be applied to it.
Both data files and equality delete files are stored in Parquet format, which embeds column-level statistics (min/max values). This makes it possible to apply only the equality delete files that could plausibly affect a given data file — skipping those whose value ranges don't overlap.
Example — to reconstruct the current table state:
Reading the first data file: all equality delete files are loaded, a set of unique values is built, and a filter is constructed from it;
Reading the second data file: a filter is built from only the last equality delete file. The penultimate one is skipped because its min/max values don't overlap with those of this data file;
Reading the last data file: no filter is applied, since there are no equality delete files with a higher SequenceNumber.
Cache lifecycle
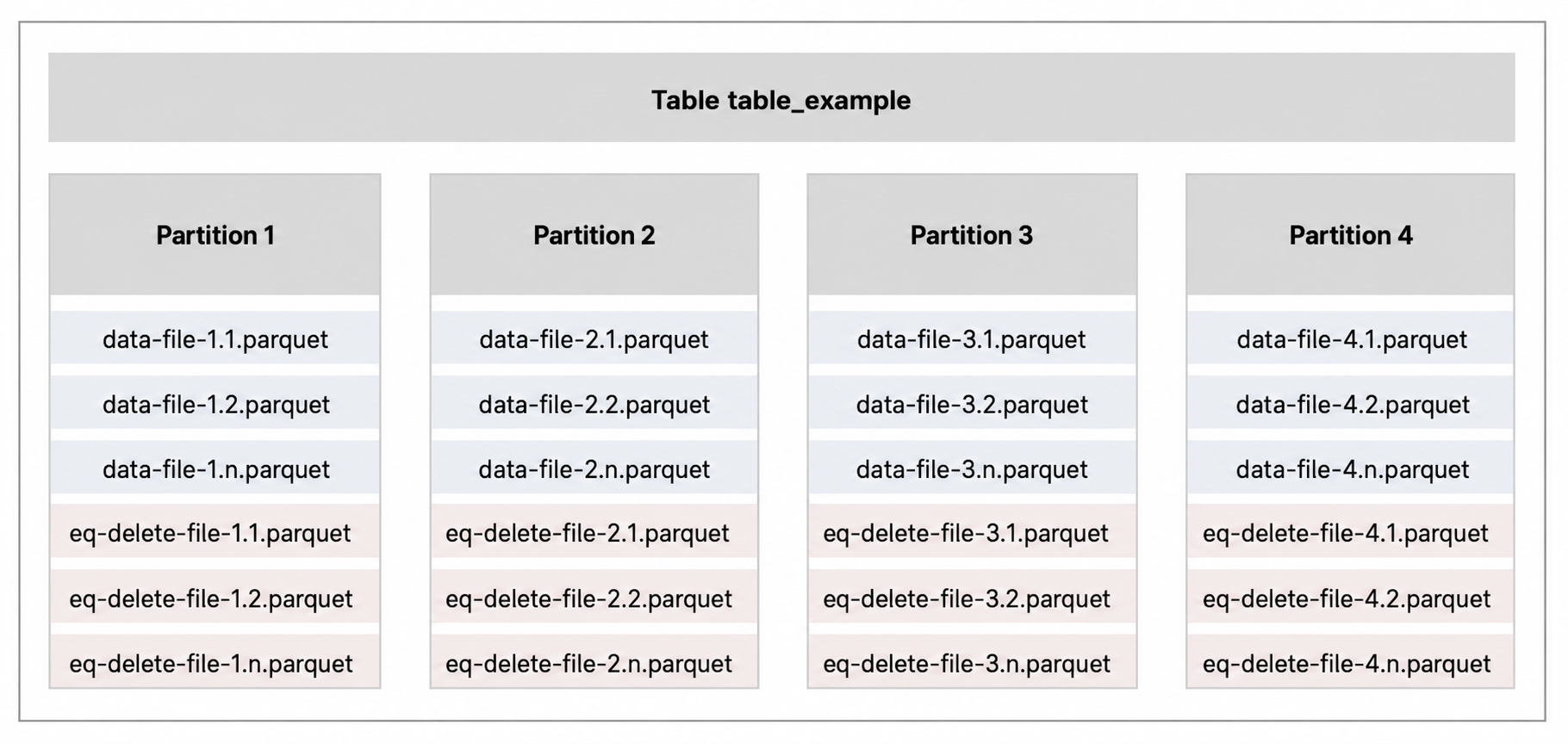
In Apache Iceberg's table storage layout, the table directory is split into independent partition subdirectories. At read time, each partition can be treated as a self-contained entity. Equality delete files within a given partition are only relevant to that partition.
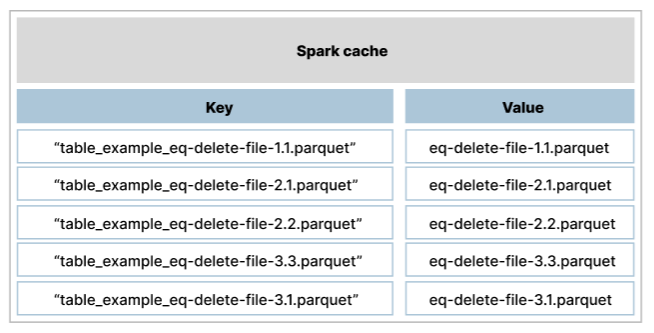
The Spark cache lifecycle, however, is table-scoped rather than partition-scoped. Cache keys are formed by concatenating the table name with the path to the equality delete file; the cached value is the raw file content. While the path implicitly encodes the partition, this information is not used in any cache logic. The cache is only cleared when processing of the entire table completes — at that point an invalidate call finds all keys belonging to the table by name and removes them.
A second lifecycle quirk: the window between when a file read begins and when it lands in the cache. A file is only placed into the cache once it has been fully read from S3. This means multiple Spark tasks can request the same file simultaneously and each load their own copy into memory before any of them has finished and populated the cache.
Problems with Standard Equality Delete Caching
Analyzing behavior against a large partitioned table, we identified three core problems with the standard read implementation:
Excessive memory consumption under parallel reads. When many tasks simultaneously request the same delete file, each may load its own copy into memory. Each task then also builds its own value set and bloom filter. This multiplies memory use on the executor, and effectively prevents using executors with high CPU counts.
Data duplication and wasted CPU work. The cache holds the raw equality delete files, which contain stale and duplicate values. Because files are stored in memory in their original (uncompressed) form, they occupy more space than necessary. Every access to these equality delete files requires re-converting them into the internal Iceberg structure, adding unnecessary CPU overhead.
Suboptimal cache lifecycle. Equality delete files belong to specific partitions. Despite this, the standard cache retains them for the full duration of the table processing job — even when a given partition has already been fully processed. Memory is held by stale data long after it is needed.
Having diagnosed these problems, we rewrote the standard equality delete file read-and-apply mechanism for Alphyn Lakehouse to address all three shortcomings.
Our implementation of equality delete read-and-apply is not open-sourced — it ships as part of the Managed Iceberg Tables functionality in Alphyn Lakehouse, so we cannot share the source code. But we can share the problem framing and the approaches we used to solve it.
Benchmark Results on a Test Environment
Test table and environment parameters:
Total table size: ~22 GB;
Compression: zstd level 3;
Number of partitions: 6;
Each successive partition contains more deletions than the previous one;
Spark 3.5.4, Iceberg 1.8.1.
Executor configurations tested: CPU: 12 to 32 cores; memory (JVM heap): 140 to 197 GB.
Experiment design. Starting from the optimal configuration for our optimized Alphyn Lakehouse Cache, determine what configuration is needed to run the same maintenance command on the same table using the standard open-source Apache Spark Cache.
Results (comparison):
# | Cache | CPU | Memory | Time | Status |
|---|---|---|---|---|---|
1 | Alphyn Lakehouse Cache | 32 | 140 GB | 8 min | Success ✅ |
2 | Apache Spark Cache | 32 | 197 GB | ~2 hours | Error (OOM) ❌ |
3 | Apache Spark Cache | 20 | 197 GB | ~2 hours | Error (OOM) ❌ |
4 | Apache Spark Cache | 12 | 197 GB | ~1 hour | Success ✅ |
5 | Apache Spark Cache | 12 | 140 GB | ~3 hours | Error (OOM) ❌ |
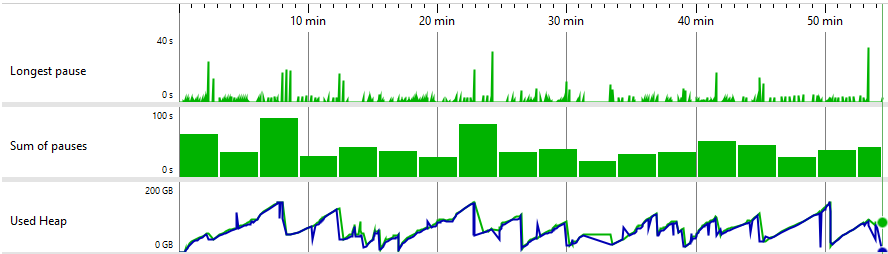
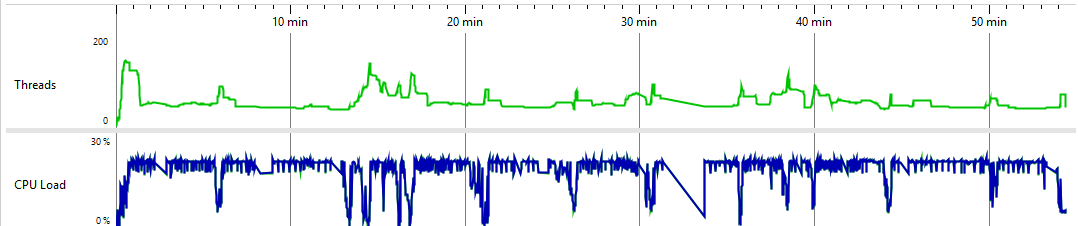
Open-source Apache Spark Cache metrics
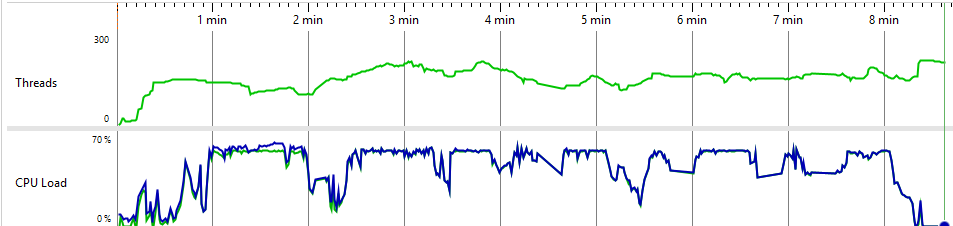
Alphyn Lakehouse Cache metrics

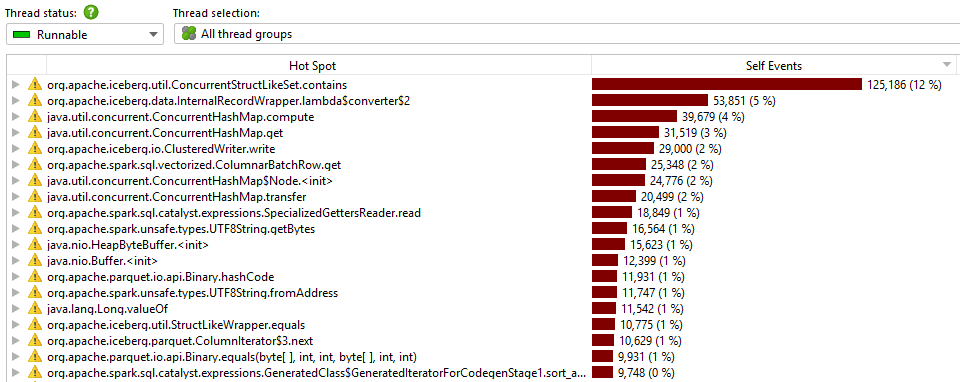
Key takeaways:
Our optimized cache completed the job at high parallelism (32 cores) with reduced memory (140 GB) in 8 minutes — while the standard cache either crashed with OOM or required a sharp reduction in parallelism to finish at all;
This confirms that deduplication and partition-scoped lifecycle management deliver meaningful gains in both memory footprint and execution time;
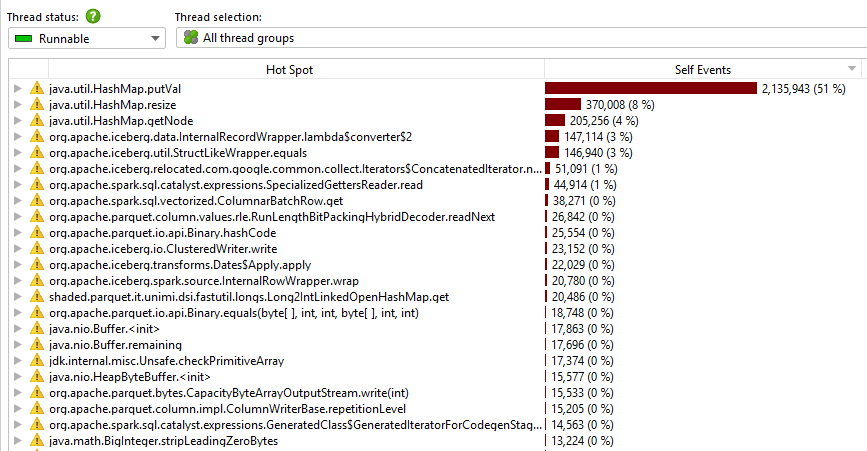
The metrics show the optimized cache can sustain higher CPU utilization thanks to greater thread-level parallelism. CPU time distribution also improved — the gap between the most expensive method and everything else narrowed considerably.
Production Validation
Summary
To validate the optimization in production, we created duplicate streams for three data pipelines and performed a full initial load into the target tables, enabling an apples-to-apples performance and maintenance-time comparison on identical data.
In parallel, we reproduced the standard maintenance schedule covering typical run modes (nightly full cycles and periodic incremental runs under varying load), and demonstrated consistent reductions in memory consumption and processing time — while maintaining or increasing parallelism in a number of scenarios.
Test table descriptions
Date-partitioned
A new partition is created daily; partition volume grows throughout the day. Maintenance runs: nightly (full cycle) and hourly.
Parameter
Apache Spark Cache
Alphyn Lakehouse Cache
Executors
5
1
Total cores (cluster)
10
9
Memory (per executor)
100 GB
71 GB
Peak actual consumption
100 GB
65 GB
Processing parallelism
10
3
Average runtime
~60 min
~45 min
Total (cluster-wide)
50 cores, 500 GB
9 cores, 71 GB
Bucket-partitioned
Equality deletes apply to files in each bucket — maintenance requires rewriting a large number of files.
Parameter
Apache Spark Cache
Alphyn Lakehouse Cache
Executors
5
1
Total cores
5
27
Memory (per executor)
100 GB
81 GB
Peak consumption
90 GB
70 GB
Parallelism
10
7
Average runtime
~21 min
~23 min
Total
25 cores, 500 GB
27 cores, 81 GB
Unpartitioned
Equality deletes potentially affect all data files, maximizing the rewrite volume.
Parameter
Apache Spark Cache
Alphyn Lakehouse Cache
Executors
5
1
Total cores
5
32
Memory (per executor)
100 GB
188 GB
Peak consumption
95 GB
170 GB
Parallelism
10
8
Average runtime
~20 min
~30 min
Total
25 cores, 500 GB
32 cores, 188 GB
Aggregate cluster impact across all three tables
Potentially freed memory: ~1,222 GB. Reduction in pod count: ~12. Freed CPU cores: ~38.
Conclusion
Equality delete is a practical and viable approach to implementing deletes and updates in Apache Iceberg for streaming scenarios. The optimizations — value deduplication, partition-scoped cache lifecycle, and faster membership checks — address the core problems and have demonstrated real-world gains in production:
significantly lower total memory allocation (~1,222 GB freed across three production tables);
reduced pod count in the Kubernetes cluster;
the ability to increase CPU density on executors;
maintained or improved execution time across the majority of scenarios.
This optimization is currently running in production client environments for all Iceberg table maintenance, and ships as part of the Alphyn Lakehouse platform.
See it on your own data
If you're weighing how this would handle your workloads, we'd be glad to walk you through Alphyn Lakehouse on a real scenario. Book a sovereign-lakehouse walkthrough →
About Alphyn.AI
We build the Alphyn Lakehouse, a Kubernetes-native, high-performance, multi-engine lakehouse for any enterprise data and analytical workload — from agentic AI and BI to structured and unstructured data. Built entirely on open standards and an open architecture, Alphyn Lakehouse is a sovereign, on-premises solution for regulated enterprises across the GCC and the wider MENA region.